Datenjournalismus
Gemeinsam mit Computer-Linguisten der Uni Stuttgart habe ich den 'DebateExplorer' entwickelt: ein Tool, das via Textmining große Mengen an Bundestagsdebatten durchsucht und erkennt, über welche Themen die Abgeordneten diskutieren. Unsere Idee dabei: wenn uns künstliche Intelligenz dabei hilft zu erkennen, wann und wo ein Politiker beispielsweise seine Meinung zu einem bestimmten Thema geändert hat, wäre das ein guter Ansatz für eine journalistische Recherche - denn vielleicht wurde er ja von außen beeinflusst, vielleicht gar in unredlicher Weise.
Ich bin überzeugt, dass Künstliche Intelligenz den Journalismus voranbringen kann. Wir müssen allerdings davon wegkommen, Datenjournalismus vorallem als einen Weg zu "schönen Infografiken" zu sehen. Er kann mehr, und er kann vorallem Investigation unterstützen. Dazu habe ich einen vieldiskutierten Beitrag im "Meta-Magazin" geschrieben.
Zum Thema Daten und zur Frage, was Journalistinnen und Journalisten mit Künstlicher Intelligenz und Data-Mining machen können und sollten, biete ich Talks und Workshops an - beispielsweise auf der Weltkonferenz der WissenschaftsjournalistInnen 2019 in Lausanne.
Hier finden sich meine Blogartikel rund um unser Projekt DebateExplorer:
- Details
- Thema: Datenjournalismus

Ich sollte glücklich sein! Ich trainiere eine Software, die den Journalisten der Zukunft die Arbeit erleichtern soll. Die investigative Recherche am Leben erhält. Ich arbeite voll am Puls der Zeit – wer würde sich nicht wünschen, auch mal eine künstliche Intelligenz mit eigenem Hirnschmalz anzureichern?
Aber manchmal holen mich die Mühen der Ebene ein: Das Bürokratendeutsch der Politiker beispielsweise. Wird eine Maschine je verstehen können, was diese vor lauter Rhetorik wirklich meinen? Sie wiederholen die Argumente der Gegenseite, bevor sie verklausuliert zu ihren eigenen Standpunkten kommen, sie verwenden ohne Ende doppelte Verneinungen, Schachtelsätze – werden meine Annotationen dem Algorithmus wirklich helfen?
- Details
- Thema: Datenjournalismus

Jetzt will ich es wissen! Wir sitzen im Besprechungsraum am Institut für Maschinelle Sprachverarbeitung und schauen gebannt auf die Leinwand, auf der Textwolken auftauchen. Wir: Stern-Investigativ-Reporter Rainer Nübel, die Computerlinguisten Andre Blessing und Jonas Kuhn und ich. Werden diese Wolken uns helfen können, Lobbyisten zu enttarnen?
Seit Jahren schreibe ich über Automatisierung, darüber, wie Maschinen uns Arbeit abnehmen können, über künstliche Intelligenz, lernende Algorithmen - und wie diese zu guten und richtigen Ergebnisse kommen, die uns weiter bringen. Eines hat sich durch viele Recherchen durchgezogen: die Erkenntnis, dass die Kombination aus Mensch und Maschine ein Erfolgsmodell ist: Maschinen sind gut darin, Muster in großen Datenmengen zu erkennen. Menschen sind gut darin zu erkennen, ob es sich um sinnvolle Muster handelt und können den Maschinen mit einigen wenigen Regeln die richtige Richtung weisen. Mit unserem Datenjournalismus-Projekt Debate Explorer habe ich erstmals die Möglichkeit, das in der Praxis zu verfolgen, worüber ich bisher nur aus der externen Perspektive geschrieben habe: selbst eine künstliche Intelligenz mit zu trainieren, die uns Journalisten in Zukunft die Fleißarbeit abnehmen könnte.
- Details
- Thema: Datenjournalismus
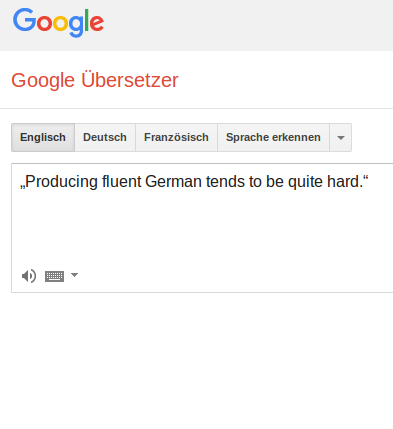
Im April 2015 bin ich auf einem Vortrag von Jonas Kuhn, Professor für Computerlinguistik an der Uni Stuttgart, über die automatische Analyse großer Textmengen. Er zeigt an beeindruckenden und einleuchtenden Beispielen, dass jene Algorithmen erfolgreich sind, die teilweise regelbasiert und teilweise selbst lernend nach Mustern suchen. Wenn Maschinen Sprache rein nach statistischen Verfahren lernen, kommen sie zwar recht weit, aber irgendwann stoßen sie an ihre Grenzen: So wird der englische Satz „Producing fluent German tends to be quite hard.“ (Es scheint schwierig zu sein, fließendes Deutsch zu erzeugen) bei Googletranslate zu dieser Zeit beispielsweise übersetzt mit „Herstellung fließend Deutsch neigt dazu, ziemlich hart.“ Also ziemlicher Buchstabenmüll.
Wenn Menschen hingegen ein paar Regeln hinzugeben, sind die Maschinen erfolgreicher, erklärt Jonas Kuhn auf seinem Vortrag. Die Herausforderung ist, die richtige Mischung herauszufinden: Die Maschine nicht zu sehr einzuschränken, aber ihr auch nicht zu große Freiheiten zu lassen, die sie auf die falsche Spur führt. Nach dem Vortrag frage ich Jonas Kuhn, ob wir nicht ein gemeinsames Projekt starten könnten: schon lange frage ich mich, inwiefern Lobbyisten Politiker beeinflussen.
- Details
- Thema: Datenjournalismus